3 dplyr
3.1 Lectura de datos
En la unidad previa caracterizamos un hogar censal. En esta unidad trabajaremos la base de datos censal, con todas sus viviendas, hogares y personas. Para esto recorreremos distintos paquetes de la familia tidyverse, cuyo fin es generar un entorno de herramientas especializada en el análisis de datos.
Pero primero haremos un repaso por las distintas opciones de lectura de datos que nos ofrece R. Creemos una carpeta que se llame “Data”, donde dejemos las bases de datos disponibles en el drive. Verifiquemos que tengamos todas las bases de datos correspondientes en la carpeta “Data” mediante list.files().
Para mostrar las diversas formas de lectura de datos que ofrece R nos valdremos de la Encuesta Permanente de Hogares (EPH), un operativo estadístico llevado adelante por INDEC con motivo de caracterizar la evolución de los mercados de trabajo de 31 aglomerados urbanos del país. Por ejemplo, si quisiéramos leer la base de datos del segundo trimestre de 2023, ¿qué opciones tenemos? ¿Qué opciones nos dan? Es muy importante aquí que la ruta del archivo a leer sea a partir de la posición de trabajo actual (recuerda getwd()) y hacia donde apuntar (puedes utilizar el predictor con tab luego de generar comillas).
- Texto plano con separador
;
# R base trae funciones para la lectura de datos, las más comunes son "read.table" y "read.csv"
EPH_2t23_txt <- read.table(file = "Data/usu_individual_T223.txt", header = T, sep = ";")
head(EPH_2t23_txt[,1:5])- Una planilla excel con extensión
xlsoxlsx, seleccionando la pestaña (y el rango de celdas si queremos). Aprovechemos a leer la documentación de esta función:?read_xlso desde el tab de paquetes en RStudio.
library(readxl) # pertenece a tidyverse
EPH_2t23_xls <- read_xlsx(path = "Data/usu_individual_T223.xlsx", sheet = 1)
head(EPH_2t23_xls)Nos interesa el rango “B3:C5”:
- También podemos leer extensiones .dbf, SAS, SPSS, Stata, etcéteras… gracias a la librería foreign. Por ejemplo, una base de datos del entorno SPSS de la EPH del primer trimestre de 2019:
- En la primer unidad dijimos que un paquete es compartir , y es lo que hace a una comunidad dinámica. Ya existe un paquete llamado eph. Permite no solo leer las bases de datos trimestre a trimestre, sino funciones para obtener muchos resultados y panelear olas. ¿Qué warning nos da?
3.1.1 Acceso a archivos no locales
También podemos leer un archivo online, por ejemplo la base de microdatos de DEIS (Dirección de Estadísticas e Información en Salud) de defunciones para los años 2005-2021. Vayamos a la web de Datos Argentina del Ministerio de Salud de la Nación, específicamente para Estadísticas Vitales, y veamos cómo obtener la dirección en la web con click derecho sobre el enlace. Tiene extensión .csv. Utilicemos la función read.csv comentada anteriormente, pero en vez de apuntar a un archivo local hagámoslo al url:
url <- "http://datos.salud.gob.ar/dataset/27c588e8-43d0-411a-a40c-7ecc563c2c9f/resource/fab9e990-865c-43c4-a643-3dbc3b70a934/download/defunciones-ocurridas-y-registradas-en-la-republica-argentina-anos-2005-2021.csv"
DEf05_21 <- read.csv(url, header = T)
head(DEf05_21)Otras opciones posibles:
Paquete con datos: por ejemplo
Con conexión a un servidor: podemos acceder a una base de datos SQL Server, Oracle, etc. desde R, leyendo (y editando) sus tablas a partir de las credenciales que tengamos asignadas.
Planillas de google: tenemos la posibilidad de leer y escribir planillas de cálculo en la nube.
API: pedidos online de información a un tercero. Por ejemplo twitter (o X ahora), o servicios específicos como el de la OMS.
3.1.2 Actividad
Seguro ya estas cansado de levantar datos: “Dame el censo” se escucha murmurar en el aula-zoom.
Trabajaremos con una muestra aleatoria de viviendas del Censo 2010 en la Ciudad Autónoma de Buenos Aires. Los datos censales provienen de un proyecto de investigación expuesto en la conferencia AEPA17, y que tiene como objetivo traducir a microdato cualquier base con formato REDATAM, y cuyos resultados para el censo 2010 de Argentina pueden verse aquí. La base allí disponible NO es oficial, por lo que sus resultados pueden no ser los publicados, pero con motivo del taller nos permite jugar con las herramientas de manipulación de datos a nivel de máxima desagregación.
Terminemos de afianzar lo visto hasta aquí. Te proponemos resolver/responder:
Chequear que todas las versiones de la base de datos de la eph que leímos tengan la misma cantidad de observaciones (filas).
¿Cuántas muertes fueron registradas en el año 2021? ¿Cuantas de mujeres? ¿Cuántas en la provincia de Santa Fe? Si, necesitas un diccionario de datos, incluido en la web.
Siguiendo con la base de defunciones, estimemos el impacto del exceso de mortalidad del año 2020 y el año 2021 (un número para cada año). Lo definiremos acá como el ratio entre las defunciones de 2020 (o 2021) respecto al promedio de los años 2017-2019.
Leer “C2010_CABA_muestra.csv” (por deafult con separador “,”) y guardarlo en un objeto llamado caba2010_br (br por bruta, aún sin cambios).
Explorar el objeto leído en el punto anterior con lo visto hasta quí, y resaltar aspectos que te llamen la atención.
3.2 dplyr
En la unidad previa caracterizamos un hogar censal. En esta unidad trabajaremos la base de datos censal, con todas sus viviendas, hogares y personas. Para esto recorreremos algunos paquetes de tidyverse, cuyo fin es generar un entorno integrado de herramientas de análisis de datos.
El paquete dplyr contiene las operaciones más comunes sobre una tabla de datos, y se volvió en los últimos años el paquete más utilizado para este fin.

Una de sus ventajas es el uso del pipe %>%, que concatena operaciones sobre el mismo objeto, verbalizando el proceso, generando fluidez en nuestro razonamiento y mejor entendimiento para un tercero. En vez de f(x) (aplicar una función f() a un objeto x) se tiene x %>% f() (tengo un objeto x y le aplico la función f()):
Previo a comenzar debes haber leído la muestra censal de CABA “C2010_CABA_muestra.csv”, haberla inspeccionado brevemente y guardado en un objeto llamado caba2010_br (ver @ref{intro}).
3.2.1 seleccionar (select), renombrar (rename)
Empecemos a trabajar la base de datos censal. Para este ejercicio nos interesa contar con la variable geográfica sobre el departamento de CABA al que pertence la vivienda, las variables de identificación de las unidades de análisis, y algunos atributos en función del cuestionario. Quedémonos con estas variables mediante la función select:
caba2010 <- select(.data = caba2010_br,
IDDPTO, VIVIENDA_ID, HOGAR_ID, PERSONA_ID,
V01, P01, P02, P03, P05)Podemos realizar la misma operación de la mano de %>%, no necesitando especificar el objeto como argumento:
caba2010 <- caba2010_br %>% select(IDDPTO, VIVIENDA_ID, V01, HOGAR_ID,
PERSONA_ID, P01, P02, P03, P05)
# léase: toma el objeto *** y selecciona las columnas ***Si quisiéramos quedarnos solo con las variables de persona podríamos usar starts_with("P") dentro de select (o también PERSONA_ID:P05, ¡probalo!). Existen muuuchas más funcionalidades útiles para tablas con muchas columnas.
Nótese que estamos pisando el mismo objeto. Luego podemos renombrar algunas variables para hacer su uso más fluido, mediante rename:
# NuevoNombre = ViejoNombre
caba2010 <- caba2010 %>% rename(Tipo_Viv = V01, Rel_Par = P01, Sexo = P02, Edad = P03, nativo = P05)
# Tambien es posible por posiciónHabrás notado una de sus ventajas: la referencia al nombre de las variables no requiere $ ni “[,]” como en R Base. Podemos condensar lo anterior y hacerlo todo en un paso utilizando %>%. Implica algo super útil: un nuevo %>% supone el objeto ya modificado.
caba2010 <- caba2010_br %>%
rename(Tipo_Viv = V01, Rel_Par = P01, Sexo = P02, Edad = P03, nativo = P05) %>%
select(IDDPTO, VIVIENDA_ID, HOGAR_ID, PERSONA_ID,
Tipo_Viv, Rel_Par, Sexo, Edad, nativo)¿Lo que estamos generando es un data.frame? ¿Qué es un tibble?
3.2.2 Actividad
Crear un data.frame llamado “caba2010_a” que contenga solo las variables identificatorias (que tienen un “ID”) de “caba2010_br”. Puedes utilizar la función
contains(leer ejemplos).Renombrar las variables de manera que siempre comiencen con “ID_” (en vez de VIVIENDA_ID que sea ID_VIVIENDA).
Contar la cantidad de columnas mediante
ncol()y corrobar que la cantidad de variables sea menor a las de “caba2010_br”.
3.2.3 resumir (summarise) por grupos (group_by)
Como analistas nos interesa calcular medidas resumen para poder obtener conclusiones, plantear hipótesis o simplemente conocer más el fenómeno relevado/registrado en los datos. Si quisiéramos saber cuántas personas existen en nuestra muestra de CABA podemos realizar un summarise (resumen) de los datos mediante la función n() (contar filas):
Para contar cuántas viviendas fueron relevadas en la base debemos considerar casos con valor distinto en la variable de código de vivienda VIVIENDA_ID:
¿Cuál es el promedio de personas por vivienda?
Cóctel propio
¿De qué forma podríamos hacer lo anterior en R base (nrow,ncol,unique)? La experiencia de usuario de cada uno define el mix de herramientas que le es más cómodo/útil según la complejidad de cada tarea.
Con summarise podemos aplicar cualquier función resumen sobre los datos. Por ejemplo: ¿Cuál es la edad promedio de las personas? ¿Cual es la edad máxima reportada?
¿Podemos incluir todo lo anterior en una sola sentencia? ¡Esa es la magia de %>%!
caba2010 %>%
summarise(n_personas = n(),
n_viviendas = n_distinct(VIVIENDA_ID),
n_hogares = n_distinct(HOGAR_ID),
pers_x_viv = n_personas/n_viviendas,
pers_x_hog = n_personas/n_hogares,
hog_x_viv = n_hogares/n_viviendas,
edad_media = mean(Edad),
edad_max = max(Edad)
)Las operaciones principales que podemos realizar mediante summarise las podés ver acá.Pero su utilidad se potencia cuando queremos resumir una variable segmentando por grupos. Esta agrupación antecede a summarise, y requiere ser indicada con group_by incluyendo como argumento las variables de agrupación. Por ejemplo, para conocer la cantidad de personas y viviendas relevadas por Departamento (Comuna):
pers_viv_dpto <- caba2010 %>%
group_by(IDDPTO) %>%
summarise(n_personas = n(),
n_viviendas = n_distinct(VIVIENDA_ID))Seguro estas cantidades difieren según código de tipo de vivienda. Pero primero podemos agregar la variable que describe los códigos. Carguemos como objeto el diccionario e incorporémoslo:
cod_tipo_viv <- data.frame(Tipo_Viv = 1:10,
Tipo_Viv_descripc = c("Casa",
"Rancho",
"Casilla",
"Departamento",
"Pieza en inquilinato",
"Pieza en hotel familiar o pensión",
"Local no construido para habitación",
"Vivienda móvil",
"Persona/s viviendo en la calle",
"Sin Dato"))
caba2010 <- caba2010 %>% left_join(cod_tipo_viv, by = "Tipo_Viv")Joins!!!
dplyr tiene las funciones típicas de join para el pareo de data.frames dependiendo la relación que desiemos. Ver más aquí.
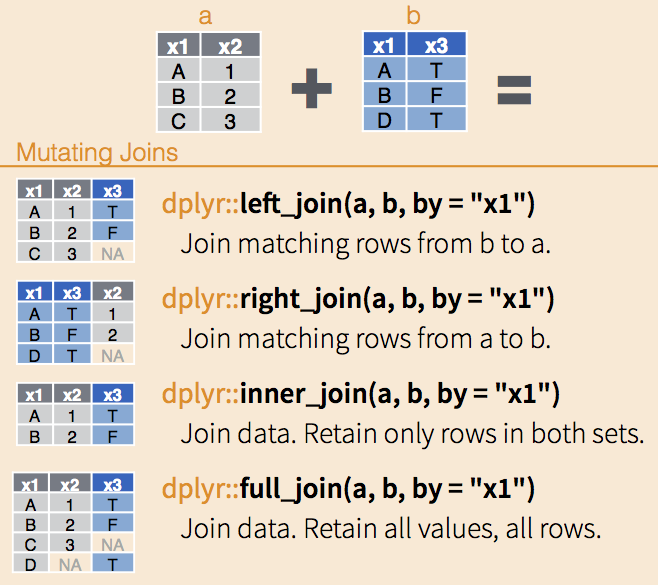
¿Por qué hay valores NA en Tipo_Viv_descripc? Veamos qué código es el problemático creando una tabla de contingencia entre códigos y etiquetas: podemos usar la función count para descubrirlo: caba2010 %>% count(Tipo_Viv, Tipo_Viv_descripc).
Ahora sí, obtegamos el promedio de personas por vivienda según tipo:
pers_tipoviv_dpto <- caba2010 %>%
group_by(IDDPTO, Tipo_Viv_descripc) %>%
summarise(n_personas = n(),
n_viviendas = n_distinct(VIVIENDA_ID),
pers_viv = n_personas/n_viviendas)Parece una tabla muy grande (¿cuántas filas tiene?). Si querés mirar la tabla: View(tabla).
3.2.4 transformar (mutate), filtrar (filter), ordenar (arrange)
Mediante mutate podemos crear variables nuevas que pueden o no relacionarse a las existentes. Tomando la tabla pers_viv_dpto (sin distinguir tipo de vivienda), podemos calcular el ratio de personas por vivienda segun departamento ratioPV:
# a que base nos referimos
head(pers_viv_dpto)
# creo una variable (sin resumir como en summarise)
pers_viv_dpto <- pers_viv_dpto %>% mutate(ratioPV = n_personas / n_viviendas)
# Nos avisan desde INDEC que hay una hipótesis a corroborar de subenumeración de personas del 2% y de viviendas del 1%. Calculemos un indicador alternativo bajo esa hipótesis:
pers_viv_dpto <- pers_viv_dpto %>% mutate(ratioPV_altern = n_personas * 1.02 / n_viviendas * 1.01) Para conocer qué departamentos poseen mayor promedio, podemos ordernar la tabla mediante arrange:
pers_viv_dpto <- pers_viv_dpto %>% arrange(ratioPV)
# mejor al revés: descendente
pers_viv_dpto <- pers_viv_dpto %>% arrange(desc(ratioPV))Si solo querés mostrar los tres departamentos con mayor valor, podés utilizar slice para seleccionar filas:
¿Tiene lógica esto?
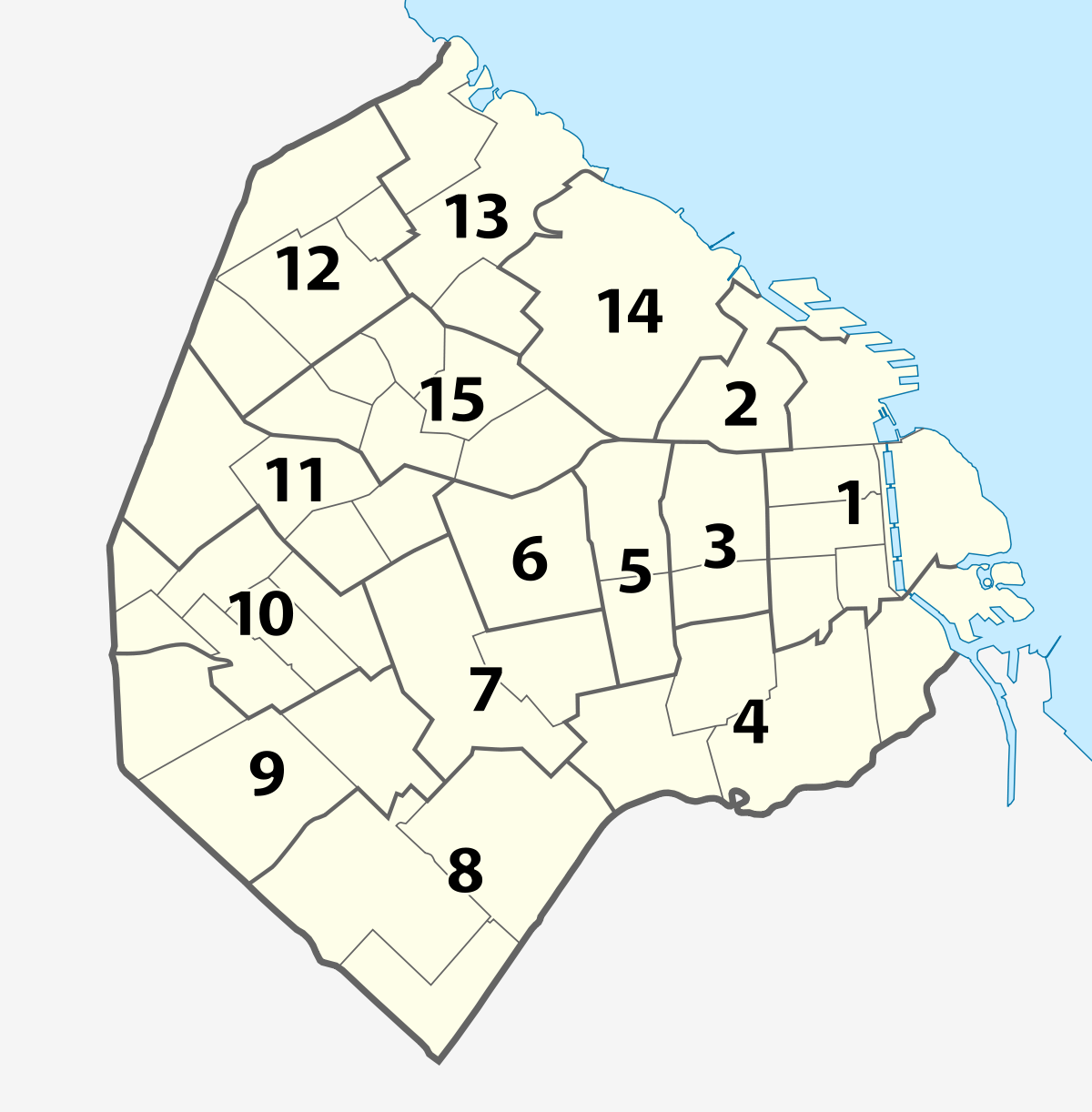
También puedes filtrar la base a un subconjunto del universo que cumpla determinadas condiciones utilizando filter. Por ejemplo, si quisiéramos conocer el indicador solo para las comunas al sur:
comunas_al_sur <- c(8,4)
pers_viv_dpto %>% filter(IDDPTO %in% comunas_al_sur) # Operador lógico! ¿te acordás?Vayamos hacia algo un poquito más complejo. Si quiero obtener la misma tabla anterior pero solo para viviendas que sean casas, casillas, ranchos o departamentos (códigos 1 a 4, viviendas individuales de mayor frecuencia), y que no sean hogares no unipersonales.
Comencemos por crear el data.frame con ese listado:
# busco un listado de hogares que cumplan ambas condiciones:
hogares_NoUnipersonales <- caba2010 %>%
filter(Tipo_Viv<5) %>%
group_by(HOGAR_ID) %>%
summarise(n_personas = n()) %>%
filter(n_personas>1) %>%
select(HOGAR_ID)
# incluimos las tres unidades de análisis en una sentenciaAhora calculemos el indicador filtrando aquellos hogares obtenidos anteriormente. ¿Los resultados son razonables?
PersVivNoUnip_Dpto <- caba2010 %>%
filter(HOGAR_ID %in% hogares_NoUnipersonales$HOGAR_ID) %>%
group_by(IDDPTO) %>%
summarise(ratioPV = n() / n_distinct(VIVIENDA_ID)) %>%
arrange(desc(ratioPV)) %>%
slice(1:3)Si tuviéramos que relatar lo que estamos haciendo, sería algo del tipo: “toma CABA2010, filtralo, agrupalo y calcula por cada grupo el indicador (creando la variable); finalmente selecciona qué quieres mostrar”. Es una ¡composición de funciones!.
Otra operación común es la de calcular distribuciones en una variable, segmentando con determinada agrupación. Podemos ver el porcentaje de mujeres dentro de cada departamento. Considerar que cualquier operación resumen (media, suma, contar) en un data.frame agrupado resumirá por grupos. Aprovechemos eso:
Porc_mujeres <- caba2010 %>%
group_by(IDDPTO, Sexo) %>%
summarise(N = n()) %>%
mutate(porcM = N/sum(N) * 100) %>% # sum() es por grupos tambien!
filter(Sexo == "m") %>%
select(IDDPTO, porcM)En el caso de que querramos la distribución por grandes grupos de edad, podemos recodificar la edad con la función case_when en una nueva variable.
distr_edadGG <- caba2010 %>%
mutate(Edad_GG = case_when(
Edad < 15 ~ "0-14",
Edad >= 15 & Edad < 65 ~ "15-64",
TRUE ~ "65+")) %>%
group_by(IDDPTO, Edad_GG) %>%
summarise(N = n()) %>%
mutate(GG = N/sum(N)*100) %>%
select(IDDPTO, Edad_GG, GG)Otras opciones de recodificación son ifelse la opción base de R y recode.
3.2.5 Actividad
Crea un nuevo objeto con el nombre que desees a partir de CABA2010_br renombrando las variables a tu gusto para que los nombres guarden relación con su contenido.
Ordénala de la siguiente manera: ascendente ID de departamento, ascendente en ID de hogar, y decreciente en la edad.
El hogar identificado como 613 no debería ser incluido en la base. Removerlo utilizando
filter.Podrías encontrar las viviendas (sus ID) que poseen más de un hogar? ¿Cuántas son y qué porcentaje representa del total de viviendas?
La variable nativo debería ser 0 (nativo) y 1 (no nativo). Sabiendo que en CABA había mas nativos que no nativos en 2010, inferir a que corresponde cada código y recodificar la variable manteniendo el tipo numerico/entero.
Filtra por aquellas comunas costeras.
Mediante la función mean obtén el promedio de edad de las comunas del punto anterior, mostrando el resultado según las más envejecidas primero.
Realiza todo lo anterior en una sola sentencia.
En una sola sentencia obtén la edad mediana por tipo de vivienda. ¿qué ves de interesante?
Obten el promedio de edad de las personas mayores a 64 años cumplidos, según departamento y sexo. Puedes utilizar algo muuuy útil: filtros dentro del argumento de
summarise:summarise(edad_media_65mas = mean(Edad[Edad>64])).Identifica (toma el ID de) un hogar cualquiera con 5 miembros.
3.2.6 Recursos adicionales
De Grande, Pablo (2016). El formato Redatam. Estudios demográficos y urbanos, 31, 3 (93) 811-832.
r4ds. Una biblia que debés llevar bajo el brazo.
dplyr: web del paquete.
Hoja de ayuda (o “cheat sheet”).